Revisiting the concurrency design of Networks’ course project
Recently during a conversation about a concurrency problem which I faced while working on an internal project at @hackcave, I came to realize that the course project for Computer Networks that I made during the fall semester of 2017 was concurrent but not parallel.
I was initially of the thought that the thread-based design which I had come up with was parallel. However, there was one thing which I didn’t take into account - GIL. I find it weird that I didn’t pay attention to this while thinking about the design back then, as I’m pretty sure of being aware of the GIL at the time. Maybe the pressure of multiple deadlines during that particularly heavy semester made me skip this one fine detail (petty excuses).
A brief background
During the first week of Jan ‘19, I was working on a specific task where DB writes were causing latency in the main thread and had to be separated. The solution to this was fairly simple - create a separate process for performing the writes, and use a shared message queue for communicating the relevant parameters. It is a single-writer single-reader problem, and Python’s multiprocessing seemed like an appropriate choice.
My course project for Computer Networks was a streaming protocol inspired by RTP. Our group mainly focussed on the broadcast part, where a single-writer retrieves the frames from a webcam and sends it to all the active readers. It was based on a multi-threaded model, and one of the primary challenges was to design a lock-free payload queue (where each payload is a collection of frames). The details of the design are available in the project report.
In retrospect, the project was a great learning experience. However, there are a couple of downsides with the approach used -
- The model isn’t parallel due to GIL
- Manually introducing thread switches (via sleep) to enforce proper ordering of reader/writer seems to be a wasteful approach
There are two alternative approaches I can think of at the time, outlined below.
Multiplexing
Multiplexing is something which I have been willing to try for a long time, and this seems like a perfect use case. I’ll be updating this segment of the blog once I get a chance to experiment with multiplexing in this project.
Message passing
A relatively simplified approach to this problem is a multi-process message passing model. It is simple to implement and also circumvents the issues in the previous model.
I did a complete rewrite of the project using rabbitmq’s fanout exchange. Interestingly, there is a 66% reduction in the SLOC, and the logic is much more straightforward. The implementation is available here.
Benchmarks
Below are the graphs plotted against data generated for a duration of 20 seconds. The script used to generate the plots is available here.
Let’s study the single client case first.
Single client (multi-threaded model)
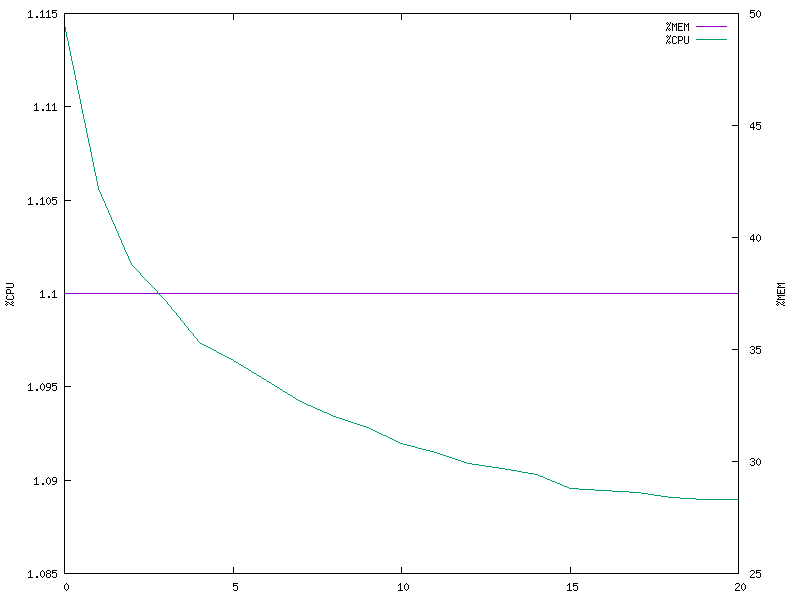
Single client (multi-process model)
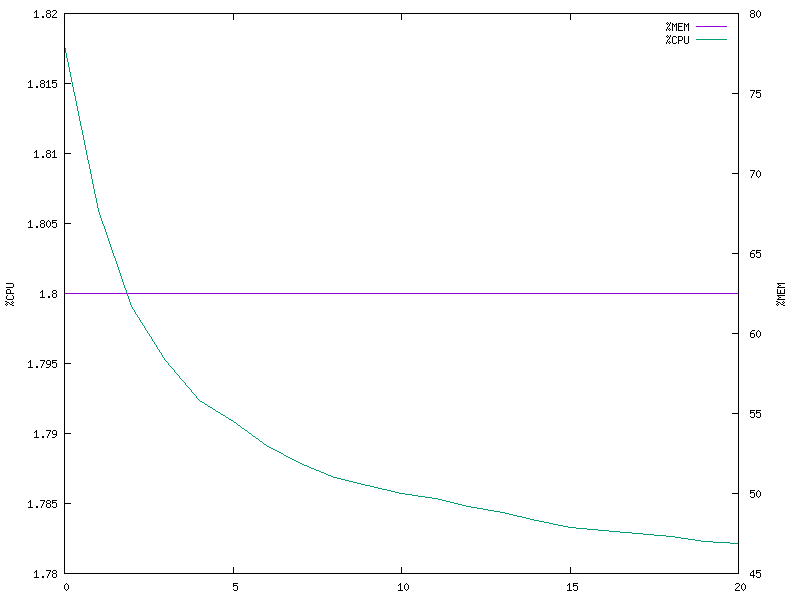
It is apparent from the plots that the multi-threaded model is better in terms of CPU utilization and also stabilizes at a lower memory footprint. The memory utilization is perfectly constant for both the models, which was a bit unexpected to me.
Let’s see the plots for a multi-client setup with 5 clients.
5 clients (multi-threaded model)
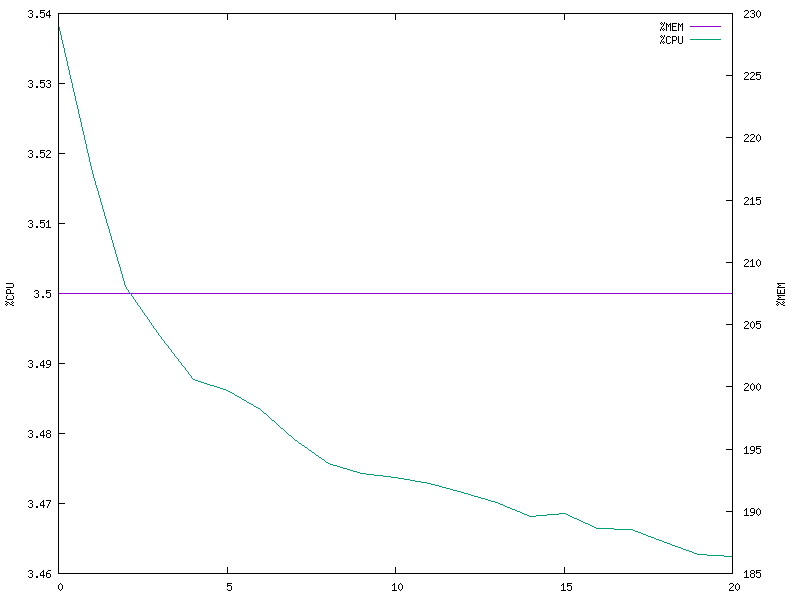
5 clients (multi-process model)
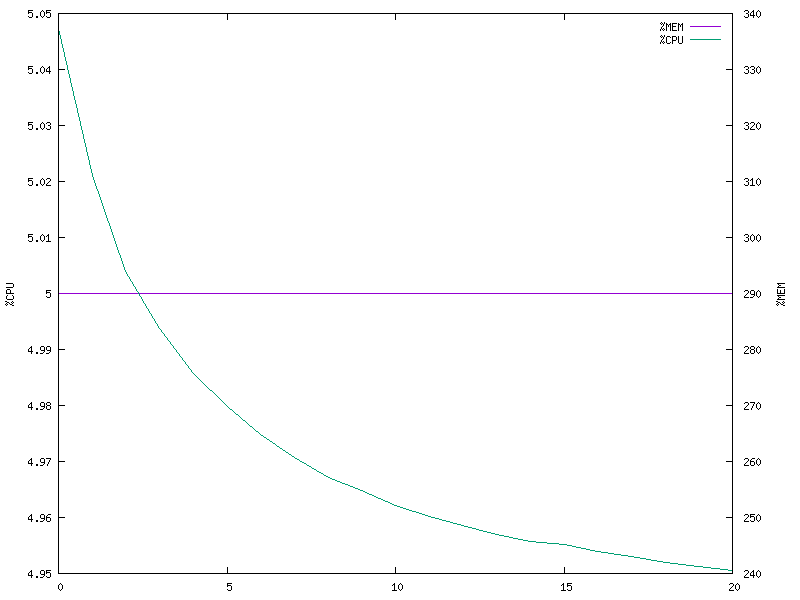
The observation here is the same as the previous case.
Conclusion
The lower memory footprint of the thread based model was no surprise to me, although I didn’t expect it to have better CPU utilization than the message passing model. I’m still skeptical whether it will have the upper hand for an even more significant number of clients, and will continue experimenting in case I find something interesting to share.
It should be noted that the measurements corresponding to rabbitmq might not be precise. I’ll make the relevant updates in case I find a better approach to get accurate metrics for rabbitmq.
Update: I experimented a bit more with an increased number of clients. For the case with 20 clients, the benchmarks are available here. The performance of both the models, in this case, is terrible (lagging and unsynchronised video) and hence I’m not sharing them here.
The compelling case is the one with 10 clients. The performance of both models is comparable to the single client case, but resource utilization is quite interesting.
To make more sense of the data, this time I recorded the observations for twice as long as before (40 seconds).
10 clients (multi-threaded model)
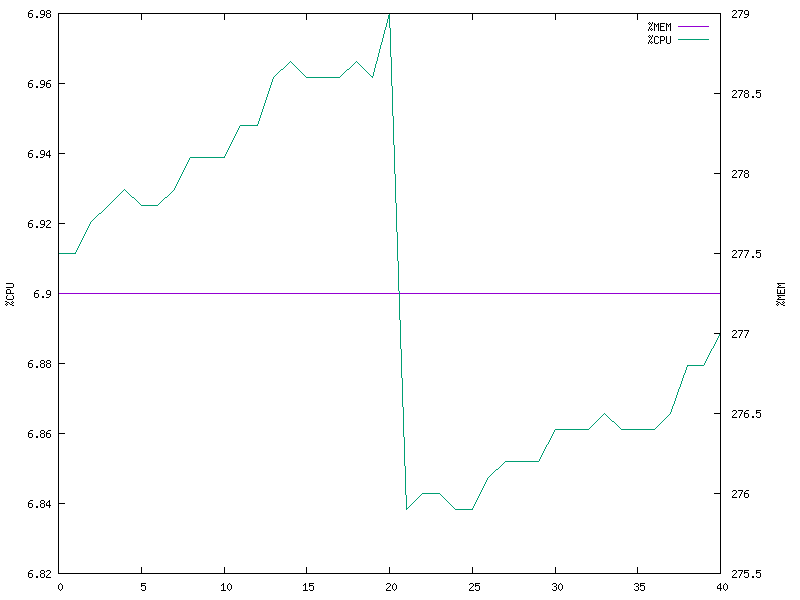
10 clients (multi-process model)
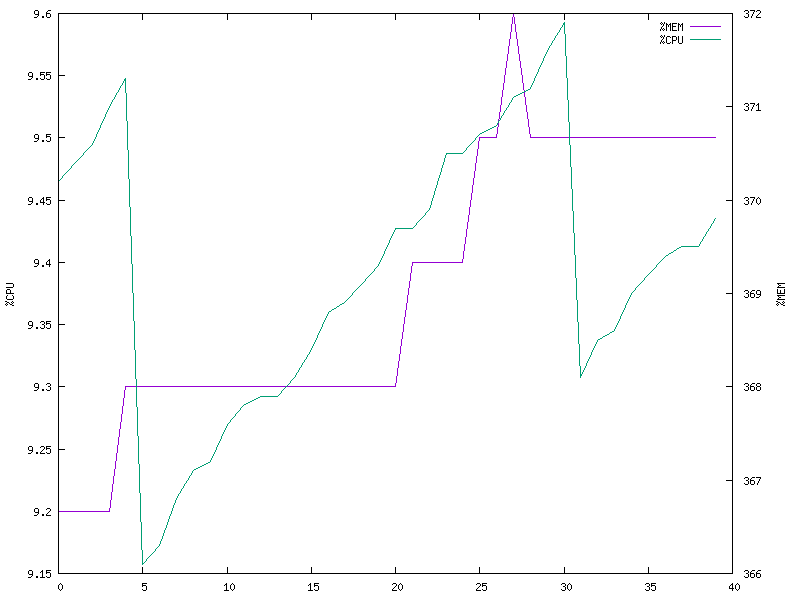
A few observations -
- The multi-threaded model still has better performance. The video quality is also comparable, however I’d say the video was more synchronised across clients in the case of multi-process model.
- The memory usage of the multi-process model is no longer constant.
- The CPU utilization in both cases experiences a sudden drop periodically. I’m not yet sure what might be the cause (todo).
Leave a Comment